카프카의 동작 방식과 원리
카프카는 기본적으로 메세징 서버로 동작
메세지라고 불리는 데이터 단위를 보내는 측(Publisher 또는 Producer)에서 카프카에 토픽이라는 각각의 메세지 저장소에 데이터를 저장하면, 가져가는 측(Subscriber 또는 Consumer)이 원하는 토픽에서 데이터를 가져가게 되어 있다.
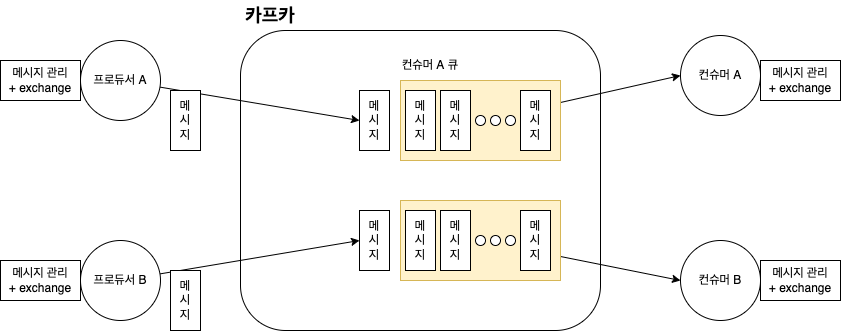
- 프로듀서는 새로운 메세지를 카프카로 보낸다.
- 프로듀서가 보낸 메세지 토픽에 도착해 저장된다.
- 컨슈머는 카프카 서버에 접속하여 새로운 메세지를 가져간다.
카프카의 특징
프로듀서와 컨슈머의 분리

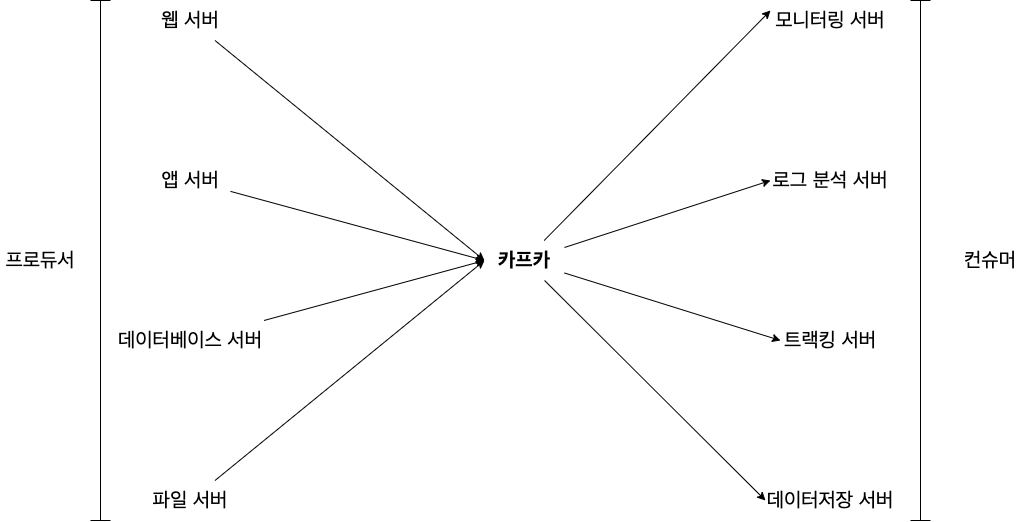
위의 두 그림을 비교해봐도 구조가 매우 단순해졌으며, 각각의 서비스 서버들은 모니터링이나 분석 시스템의 상태 유무와 관계없이 카프카로 메세지를 보내는 역할만 하면 되고, 마찬가지로 모니터링이나 분석 시스템들도 서비스 서버들의 상태유무와 관계없이 카프카에 저장되어 있는 메세지만 가져오면 된다.
멀티 프로듀서, 멀티 컨슈머
카프카는 하나의 토픽에 여러 프로듀서 또는 컨슈머들이 접근 가능한 구조로 되어있다.
즉, 하나의 프로듀서가 하나의 토픽에만 메세지를 보내는 것이 아니라 하나 또는 하나 이상의 토픽으로 메세지를 보낼 수 있다. (컨슈머도 마찬가지)
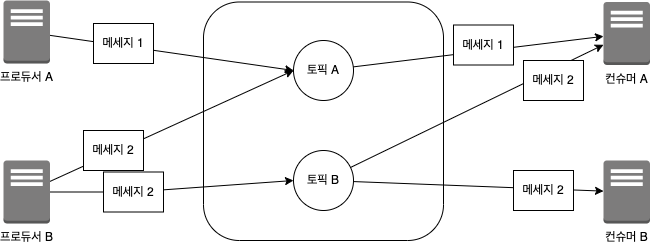
멀티 프로듀서와 멀티 컨슈머를 구성할 수 있기 때문에 카프카는 중앙 집중형 구조를 구성할 수 있게 된다.
디스크에 메세지 저장
카프카가 기존의 메세징 시스템과 가장 다른 특징 중 하나는 바로 디스크에 메세지를 저장하고 유지하는 것이다.
일반적인 메세징 시스템들은 컨슈머가 메세지를 읽어가면 큐에서 바로 메세지를 삭제한다.
하지만, 카프카는 컨슈머가 메세지를 읽어가더라도 정해져 있는 보관 주기 동안 디스크에 메세지를 저장해둔다.
트래픽이 일시적으로 폭주해 컨슈머의 처리가 늦어지더라도 카프카의 디스크에 안전하게 보관되어 있기 때문에, 컨슈머는 메세지 손실 없이 메세지를 가져갈 수 있다.
또한, 컨슈머에 버그가 있어 오류가 발생했다면, 컨슈머를 잠시 중단하고 버그를 찾아 해결한 후 컨슈머를 다시 실행할 수 있다.
이러한 방법으로 작업하더라도 메세지가 디스크에 저장되어 있기 때문에 메세지 손실 없이 작업이 가능하다.
확장성
카프카는 확장이 매우 용이하도록 설계되어 있다.
확장 작업은 카프카 서비스의 중단 없이 온라인 상태에서 작업이 가능하다
-> 카프카 클러스터를 확장하는 방법은 추후에 다룰 예정
높은 성능
고성능을 유지하기위해 카프카는 내부적으로 분산 처리, 배치 처리 등 다양한 기법을 사용하고 있다.
-> 추후에 다룰 예정
카프카 용어 정리
- 카프카
- 아파치 프로젝트 애플리케이션 이름
- 클러스터 구성이 가능하며, 카프카 클러스터라고 부른다.
- 브로커
- 카프카 애플리케이션이 설치되어 있는 서버 또는 노드
- 토픽
- 프로듀서와 컨슈머들이 카프카로 보낸 자신들의 메세지를 구분하기 위한 네임으로 사용
- 많은 수의 프로듀서, 컨슈머들이 동일한 카프카를 이용하게 된다면, 메세지들이 서로 뒤섞여 각자 원하는 메세지를 얻기가 어렵게 되기 때문에 토픽이라는 이름으로 구분하여 사용하게 된다.
- 파티션
- 병렬처리가 가능하도록 토픽을 나눌 수 있고, 많은 양의 메세지 처리를 위해 파티션의 수를 늘려줄 수 있다.
- 프로듀서
- 메세지를 생산하여 브로커의 토픽 이름으로 보내는 서버 또는 애플리케이션등을 말한다.
- 컨슈머
- 브로커의 토픽 이름으로 저장된 메세지를 가져가는 서버 또는 애플리케이션등을 말한다.
참조
카프카, 데이터 플랫폼의 최강자 - 저자/ 고승범
댓글